Parquet原理详解

Parquet原理详解
孙杨洋Apache Parquet 是一种高效的列式存储格式,其设计初衷是优化大规模数据处理的性能与存储效率。在大数据领域,随着数据规模的迅速增长,如何高效地存储、读取和处理数据已成为关键问题。作为 Apache 软件基金会支持的开源项目,Parquet 凭借卓越的数据压缩率和快速查询能力,被广泛应用于各类大数据处理场景。本文旨在从理论与实践的双重视角,系统分析 Apache Parquet 的设计理念、核心架构与技术实现,特别是其在处理复杂嵌套数据结构方面的独特优势,期望为研究者和开发者提供深入的理解与指导。
1. 基础概念
1.1 列式存储 VS 行式存储
行式存储:行式存储是将一行数据的所有字段连续存储在一起。例如,对于下表中的数据:
| id | latitude | longitude | timestamp |
|---|---|---|---|
| 23 | 106.551556 | 29.563761 | 1732118400 |
| 46 | 106.480989 | 29.600298 | 1732161600 |
| 99 | 106.512051 | 29.583541 | 1732183200 |
在行式存储中,数据会按照以下方式存储:
1 | 23, 106.551556, 29.563761, 1732118400 |
每一行的数据被紧密地存储在一起,这样的存储方式便于对单行数据的增、删、改、查操作。 在行式存储模式下,整行数据的存取非常高效,尤其是在需要获取或修改完整的一行数据时,能够显著提高访问效率。行式存储的优点:
- 快速定位整行数据:行式存储能够快速定位到某一行的数据。例如,当查询id=46的数据时,只需从存储中直接读取这一行,所有字段都能一次性高效返回。
- 事务操作支持好:行式存储非常适合高频的增删改操作,例如修改id=23这一行的timestamp值。这种操作只需要定位到该行并进行更新,整体效率非常高。
如果需要查询或更新id=46的所有数据,行式存储可以快速定位到”46, 106.480989, 29.600298, 1732161600”这一整行数据,并进行操作,而无需访问其他数据,因而效率非常高。行式存储特别适合 OLTP(在线事务处理)场景,电商系统、银行系统等需要频繁处理单条记录的增删改操作的应用中,行式存储表现尤为出色。
列式存储:与行式存储不同,列式存储将同一列的数据连续存储在一起。对于上面的示例表格,列式存储方式如下:
1 | id: 23, 46, 99 |
在这种存储模式下,每列的数据在物理存储中是连续存放的,列与列之间的数据相互独立。列式存储更适合对某些列进行查询,例如在大数据分析中仅需要查询latitude和longitude,而无需加载其他字段。列式存储的优点:
- 按列查询性能高:在数据分析场景中,查询操作往往只涉及少数列,例如筛选latitude接近106.5的数据。在列式存储中,只需读取 latitude列即可,这显著减少了 I/O 操作和内存占用,提高了查询效率。
- 压缩效果好:由于同一列的数据类型相同且分布相似,列式存储能够实现高效压缩。例如,timestamp列的值有一定规律性,这样的数据在列式存储中可以被压缩得非常紧凑,从而节省存储空间并加速处理。
如果需要查找所有记录的latitude,列式存储只需要读取106.551556, 106.480989, 106.512051这一列的数据,跳过其他列的数据,减少了读取不必要数据的开销,这对于大规模数据分析非常高效。 列式存储非常适合OLAP(在线分析处理)场景,尤其在数据仓库、大规模数据分析等需要对大量数据进行聚合、过滤和统计计算的应用中,列式存储能够显著提高查询效率。
2. Parquet详解
2.1 数据模型
Parquet采用了一个类似Google Protobuf的协议来描述存储数据的schema,以下面这个schema为例介绍Parquet的数据模型。
1 | message SpatialTemporalData { |
在这个schema中,每条记录代表一条轨迹。每条记录中有且仅有一个id,每个id可以对应0个或多个speeds和trajectory。每个trajectory必须包含一个timestamp,location字段则为可选字段。每个location必须包含唯一的latitude和longitude。在 schema的顶层是message,它可以包含多个字段。每个字段具有三个属性:重复性(repetition)、类型(type)和 名字(name)。
字段的重复性包含三种:
- required:有且只有一次
- optional:0次或1次
- repeated:0次或多次
字段的类型包括:
- 基础数据类型(物理上只存储基础数据类型):BOOLEAN、INT32、INT64、INT96、FLOAT、DOUBLE、BYTE_ARRAY、FIXED_LEN_BYTE_ARRAY
- 逻辑数据类型(指导如何转换成基础数据类型进行存储):
- 字符串类型:STRING、ENUM、UUID
- 数字类型:有符号整数,无符号整数 INT(8/16/32/64, true/false)
- 十进制:DECIMAL
- 时间类型:DATE、TIME、TIMESTAMP
- 嵌入类型:JSON、BSON、VARIANT
- 嵌套类型:LIST(需要三级嵌套),MAP(需要三级嵌套)
- 空值
LIST可以用repeated field来表示:
1 | repeated double speeds; |
Map可以用包含key-value对且key是required的repeated group来表示:
1 | repeated group trajectory { |
2.2 列式存储格式
在Parquet格式的存储中,一个schema的树结构有几个叶子节点(叶子节点都是基础数据类型),实际的存储中就会有多少column。 上面SpatialTemporalData的schema的树结构如图所示:

这个schema实际存储5列,如表所示:
| Column | Type |
|---|---|
| id | INT32 |
| speeds | DOUBLE |
| timestamp | TIMESTAMP |
| latitude | DOUBLE |
| longitude | DOUBLE |
2.3 Repetition and Definition Levels
Parquet文件采用按列存储的方式,但面对复杂的嵌套结构时,由于嵌套和重复的位置难以确定,恢复原始嵌套结构变得具有一定挑战性。为了解决这一问题,Parquet使用了 striping and assembly 算法,通过为每条数据增加 Repetition Levels 和 Definition Levels,实现对嵌套结构的精准还原。得益于这种设计,任意字段的恢复无需依赖其他字段,同时还支持按照原始嵌套格式对任意字段子集进行重建,大大提升了数据解析的灵活性与效率。以下面表格中的数据为例:
| id | speeds | trajectory.timestamp | trajectory.latitude | trajectory.longitude |
|---|---|---|---|---|
| 1 | [12.5, 13.2, 14.1] | 2024-11-21 10:00:00 | 40.7128 | -74.0060 |
| 2024-11-21 10:05:00 | NULL | NULL | ||
| 2 | [20.1, 21.3] | 2024-11-21 11:00:00 | 34.0522 | -118.2437 |
2.3.1 Repetition Levels
Repetition Level 用于表示当前值在路径中的重复层级,即该值位于哪个重复字段的结构中。 Repetition Level 专门用来处理重复字段。以 speeds 和 trajectory 为例:
speeds 字段
speeds 是一个列表类型字段,包含值 [12.5, 13.2, 14.1]。每个值的 Repetition Level 分别为 0、1 和 1:- 12.5 是列表的第一个值(即列表的起点),因此它的 Repetition Level 为 0。
- 后续的值 13.2 和 14.1 都属于同一个列表,表示列表的后续元素,因此它们的 Repetition Level 为 1。
trajectory 字段
trajectory 是一个 Map 类型,其键为时间戳,值为包含经纬度的结构体。对于每个 Map 键值对:- 第一个键值对(时间戳为 2024-11-21 10:00:00):这是 Map 的第一个值,因此 Repetition Level 为 0。
- 第二个键值对(时间戳为 2024-11-21 10:05:00):这是同一个 Map 中的第二个值,因此它的 Repetition Level 为 1,表示 Map 的重复部分。虽然纬度和经度的值为空,这些字段的 Repetition Level 依然为 1。
- 空值的状态不会影响 Repetition Level,而是通过 Definition Level 来表示。
2.3.2 Definition Levels
Definition Level 表示路径上有多少可选字段被定义。嵌套数据类型的一个特点是,某些字段(例如可选字段或重复字段)可以为空,或者未被定义。如果一个字段被定义了,那么它的所有父节点也都必须是已定义的。从根节点开始遍历,当某个字段的路径上某个节点为空时,我们记录当前的深度作为该字段的 Definition Level。如果某字段的 Definition Level 达到了它的最大值,就说明该字段是有数据的。对于必须字段(如 required 类型),字段始终是定义的,因此 Definition Level 不需要特别标明。而对于可选字段(如 optional 类型),Definition Level 用于区分字段是未定义(为空)还是有值。在关系型数据中,Definition Level 为 0 表示字段未定义,1 或更高表示字段已定义并可能有值。
- 在 speeds 字段中:
- speeds 是一个列表字段,其元素是可选的。当列表中某个元素有值时,例如 12.5,它的 Definition Level 为 1,表示该元素被定义且有数据。
- 如果 speeds 列表为空,Definition Level 为 0,表示 speeds 未被定义。
- 在 trajectory 字段中:
- trajectory 是一个 Map 类型字段,键为时间戳,值为嵌套的纬度和经度字段。
- 当时间戳键值对中,纬度和经度都有值时,例如 latitude = 40.7128 和 longitude = -74.0060,Definition Level 为 2,表示字段完全定义且有值。
- 如果某个时间戳的纬度和经度值为空(例如 timestamp 为 2024-11-21 10:05:00 的键值对),Definition Level 会降为 1,表示字段已定义但没有数据。
- 如果整个 trajectory 字段为空,Definition Level 为 0,表示字段未被定义。
2.3.3 计算过程
以下是第一条和第二条数据的 Repetition Level (R) 和 Definition Level (D) 的计算过程整合:
对于第一条数据:
- id 是标量字段,没有嵌套或重复,Repetition Level (R) 固定为 0,Definition Level (D) 固定为 0,表示字段始终定义并有值。
- speeds 是一个列表,第一个元素 12.5 表示列表的起点,因此 R=0,D=1;后续的 13.2 和 14.1 属于同一列表,因此 R=1,D=1,表明字段存在且有值。
- trajectory.timestamp 是Map的键,第一个键值对2024-11-21 10:00:00是 Map 的起点,R=0,D=2,表明键和值都定义且非空;第二个键值对2024-11-21 10:05:00是 Map 中的后续键值对,R=1,D=1,表明键已定义但值为空。
- trajectory.latitude 和 trajectory.longitude 是 Map 值中的嵌套字段,2024-11-21 10:00:00对应的纬度和经度都存在(由于是required字段,与上一层保持相同),因此 R=0,D=2;2024-11-21 10:05:00的纬度和经度为空,R=1,D=1,表示字段已定义但无值。
对于第二条数据:
- id 是标量字段,与第一条类似,Repetition Level (R) 固定为0,Definition Level (D) 固定为0。
- speeds 是一个列表,第一个元素 20.1 表示列表的起点,因此 R=0,D=1;后续的 21.3 属于同一列表,因此 R=1,D=1,表明字段存在且有值。
- trajectory.timestamp 是Map的键,只有一个键值对2024-11-21 11:00:00,因此 R=0,D=2,表明键和值都定义且非空。
- trajectory.latitude 和 trajectory.longitude 是 Map 值中的嵌套字段,2024-11-21 11:00:00对应的纬度和经度都存在,因此 R=0,D=2,表示字段已定义且有值。
| Column | Value | R | D | Column | Value | R | D |
|---|---|---|---|---|---|---|---|
| id | 1 | 0 | 0 | trajectory.timestamp | 2024-11-21 10:00:00 | 0 | 2 |
| 2 | 0 | 0 | 2024-11-21 10:05:00 | 1 | 1 | ||
| speeds | 12.5 | 0 | 1 | 2024-11-21 11:00:00 | 0 | 2 | |
| 13.2 | 1 | 1 | trajectory.latitude | 40.7128 | 0 | 2 | |
| 14.1 | 1 | 1 | NULL | 1 | 1 | ||
| 20.1 | 0 | 1 | 34.0522 | 0 | 2 | ||
| 21.3 | 1 | 1 | trajectory.longitude | -74.0060 | 0 | 2 | |
| NULL | 1 | 1 | |||||
| -118.2437 | 0 | 2 |
2.3.4 存储分析
在Parquet中,所有字段会被展平为单独的列,每列存储其实际数据,同时附加R和D两列来记录层级结构和字段状态。Parquet并不存储NULL值,而是通过D的值来判断字段是否被定义。例如,Definition Level小于最大值时表示字段为空(NULL)。对于嵌套字段和重复字段(如MAP和LIST),R的值则用于区分新记录与同一结构中的后续值。
这种设计的优点在于,它可以在保持数据层级关系的同时,避免存储冗余的层级结构信息。同时,由于R和D只需要几位就可以表示字段的状态(如7层结构只需要3bit + 3bit 就能表示R和D),存储开销极小。空字段无需存储实际值,仅通过R和D即可高效表示。这种机制使得Parquet格式在处理嵌套数据时既保持了灵活性,又显著提升了存储和读取效率。
2.4 编码与压缩技术
2.4.1 编码
编码是将数据转换为更紧凑的格式,以减少存储空间或提高计算效率。Parquet 使用了几种常见的编码方式来对数据进行编码,这些编码方式有助于在存储时减少数据的冗余,提高读取性能。
- PLAIN编码:PLAIN编码是Parquet中最基础的编码方式,它将原始数据直接存储,没有进行任何压缩或变换。该编码方式简单且高效,适用于数据分布均匀的场景,但可能会占用较多存储空间。PLAIN 编码通常用于存储不需要特别优化的字段数据,如简单的整数或字符串。
- DICTIONARY编码:DICTIONARY编码是一种通过使用字典(映射表)将数据中的重复值替换为字典索引的编码方式。该编码方法适用于有大量重复值的数据类型,比如类别型数据。在Parquet中,数据被分成多个区块,每个区块都会为该区块内的数据生成一个字典。存储时,数据中的重复项会被替换为字典的索引,进而节省存储空间。例如,如果一个字段中有多个相同的值,那么这些值将被映射为字典的索引,存储时只需保存索引而不是重复的值。这种方法能够显著降低存储空间,但需要为每个数据块生成字典,可能会增加读取时的解码开销。
- RLE(Run-Length Encoding)编码:RLE(Run-Length Encoding)编码是通过记录连续相同值的数量来压缩数据的一种方式。在数据中,若出现连续相同的值,RLE 会记录这些值出现的次数,从而将重复的数据压缩成更小的表示形式。RLE 编码特别适用于数据中存在大量连续相同值的情况。例如,如果一个字段连续出现 100 个相同的数字,那么 RLE 会将其压缩为“值+出现次数”的形式。在 Parquet 中,RLE 编码常用于布尔类型数据或者重复出现的数字类型数据。
- 位打包(Bit-Packing)编码:位打包(Bit-Packing)是一种将多个小数据类型压缩为更小比特数表示的编码方式。该方法通过打包多个值来提高存储效率,通常用于存储较小的数据类型,如整数、布尔值等。Bit-Packing 可以将每个字段中的数据值压缩为最小的比特位数,从而减少存储空间。
- DELTA 编码:DELTA编码是一种记录数据与其前一个值差异的编码方式。这种方法非常适合存储数值范围比较小且增减变化不大的数据。例如,对于一个增长规律较为平稳的数字序列,DELTA 编码将存储每个数值与前一个数值的差异,而不是存储完整的数值。这样可以显著降低存储空间,特别是对于时间序列数据或连续数据。
2.4.2 压缩
压缩是将数据进一步减少存储空间的技术。Parquet支持多种压缩算法,可以在不牺牲数据质量的情况下,进一步压缩数据以节省存储空间。常见的压缩算法包括Snappy、GZIP、LZO、Brotli等。
- Snappy压缩:Snappy 是 Google 开发的一种压缩算法,具有非常快的压缩和解压缩速度。它的压缩比虽然不如 GZIP,但由于其高效的速度,特别适合大数据处理场景中实时数据处理的需求。Snappy 通常是 Parquet 默认的压缩算法,尤其适用于对速度要求较高的场景。
- GZIP压缩:GZIP是一种较为常见的压缩算法,相较于Snappy,它的压缩比更高,但速度较慢。GZIP压缩适用于对存储空间有较高要求的场景,尤其是当存储成本较高或数据量特别大的时候。GZIP的高压缩比使得它能有效减少存储需求,但解压缩的速度可能成为瓶颈。
- LZO压缩:LZO是一种快速的压缩算法,类似于Snappy,适用于需要快速压缩和解压缩的场景。LZO的压缩比一般不如GZIP,但它的速度非常快,适合于大数据分析中对压缩速度要求较高的应用场景。
- Brotli压缩:Brotli 是由Google开发的一种压缩算法,常用于Web数据传输中的压缩。Brotli的压缩比比GZIP更高,并且其解压速度也较为高效。近年来,Brotli也开始在Parquet中被使用,尤其适用于对存储需求有较高要求的场景。
- Zstandard(ZSTD)压缩:Zstandard(ZSTD)是一种新兴的压缩算法,旨在提供比 GZIP 更高的压缩比和更快的解压速度。ZSTD 兼具了较高的压缩效率和较低的延迟,非常适合需要平衡存储与速度的应用场景。
3. Parquet具体实现
3.1 Parquet 文件存储格式中的术语
在理解 Parquet 文件的存储结构时,熟悉其中关键术语至关重要。以下是 Parquet 中一些核心术语的定义:
- **Block (HDFS 块)**:这是 Hadoop 分布式文件系统(HDFS)中数据存储的基本单元,Parquet 文件完全兼容 HDFS 的设计。Block 的大小在 Hadoop 1.x 版本中默认为 64MB,而在 Hadoop 2.x 版本中则增加至 128MB。HDFS 使用 Block 的副本机制来确保数据的冗余和容错能力,从而提高了系统的可靠性和稳定性。
- **File (文件)**:这是存储在 HDFS 上的一个逻辑实体,包含文件的元数据信息,但其实际数据内容由多个 HDFS Block 保存。
- **Row Group (行组)**:Parquet 将数据按行划分为多个逻辑上的水平分区。每个 Row Group 包含该组中所有列的列块(Column Chunk),是并行化和 IO 操作的基本单元。这样设计使得每个行组都可以独立解码,便于分布式处理。
- **Column Chunk (列块)**:指单列数据在一个行组中的物理存储。列块在行组中是逻辑连续的,这种设计允许对列进行有效的压缩和编码,从而提高了存储的利用率。
- **Page (页面)**:列块被进一步划分为多个 Page,这是 Parquet 文件压缩和编码的最小基本单元。每个列块中可能包含多个类型的 Page,例如数据页面、字典页面等。
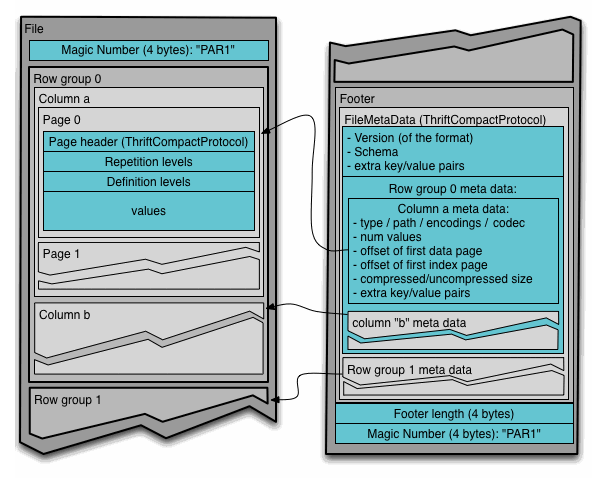
3.2 并行化执行的基本单元
在 Parquet 文件中,不同层级的数据单元在并行化处理和 IO 操作中发挥不同的作用:
MapReduce 任务划分:在使用 Hadoop 的 MapReduce 框架处理数据时,通常以 File 或 Row Group 为基本单位来分配任务,即每个任务处理一个完整的文件或者一个行组,从而实现并行化。
IO 操作:Parquet 文件的 IO 操作以 Column Chunk 为基本单位进行。这种设计方式使得可以只读取所需列的数据,减少不必要的磁盘 IO,从而提高读取效率。
编码和压缩:在 Parquet 中,编码和压缩通常以 Page 为单位进行。每个页面可以使用不同的编码方法来提高压缩率,例如使用 RLE(Run Length Encoding)对重复值进行压缩,从而降低存储空间。
3.3 Parquet 文件格式
Parquet 文件格式具有自解析的特性,文件使用 Thrift 格式定义 schema 以及其他元数据信息。这些元数据信息存储在文件末尾,方便读取时直接访问。
典型的 Parquet 文件结构如下:
- 整个文件被划分为多个行组,每个行组包含所有列的数据块和元数据信息。
- 文件的元数据存储在数据部分的最后,包含了所有列块元数据的起始位置。
这种将元数据存储在文件末尾的设计,使得在写入数据时可以顺序高效地写入文件,同时在读取文件时可以快速获取元数据并定位到相关数据块。
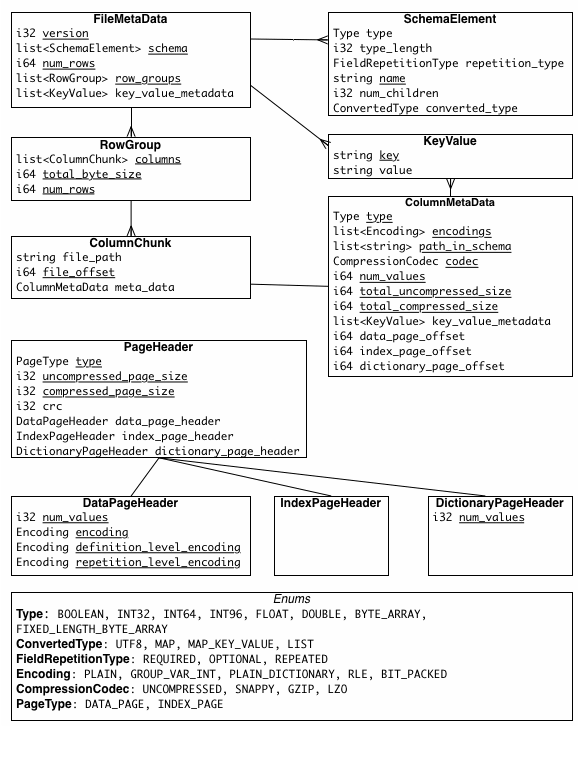
3.4 元数据信息
Parquet 文件包含三种不同类型的元数据,每种元数据在不同层级描述文件的内容和结构:
- 文件元数据:描述整个文件的结构和内容,例如行组和列块的位置信息等,是文件级别的数据概览。
- 列(块)元数据:描述单个列块的详细信息,包括该列块的属性、位置和大小。这些元数据使得读取特定列块变得更加高效。
- 页面头部元数据:描述每个页面的具体属性,包括编码方式、压缩方法、页面位置等。这些元数据对于解码和读取页面中的数据至关重要。
3.5 并行读取与列存储的优化
Parquet 的设计充分考虑了并行处理和列存储的优势。由于数据是按列存储的,因此可以非常高效地进行列的读取操作。尤其是对于只需要部分列的查询,Parquet 能够显著减少 IO 开销,提升性能。每个行组中的列块在物理上保持连续存储,这样即使是大规模并行读取也可以最大程度减少磁盘寻道时间。
3.6 编码(Encoding)
Parquet 支持多种编码方式,以优化数据的压缩和读取效率。细节可以参考官方文档:Parquet Encodings。通过采用不同的编码方法,Parquet 能够大幅度减少重复值存储,从而节省磁盘空间。
3.7 Column Chunks 存储与读取
每个 Column Chunk 是由多个 Page 组成的。在读取数据时,Parquet Reader 可以利用页面头部元数据中存储的信息,直接跳过不感兴趣的页面。例如,字典页面与数据页面存储的内容类型不同,Reader 可以根据需求决定是否需要加载某些页面,从而优化查询性能。
3.8 错误处理机制
Parquet 文件设计了一系列机制来应对数据损坏的情况,以保证数据的可用性和可靠性:
- 文件元数据损坏:如果整个文件的元数据损坏,通常情况下整个文件会无法读取。
- 列元数据损坏:如果某个列的元数据损坏,只会影响该列块的读取,其他行组中相同列的块仍可正常使用,这种设计能够减少局部损坏对整体数据的影响。
- 页面头部损坏:当页面头部损坏时,该列块中的所有后续页面将无法读取。
- 页面数据损坏:如果某个页面的数据损坏,通常只会导致该页面的数据不可用,其它页面的数据仍然可用。
较小的行组设置可以更好地抵抗数据损坏,因为损坏只会影响较小的数据范围,而不会影响整个文件。
3.9 推荐的配置参数
为了实现最佳的性能和可靠性,Parquet 提供了一些推荐配置:
行组大小(Row group size):较大的行组可以使列块变得更大,进而提升顺序 IO 的性能。虽然较大的行组需要更多的内存缓存,但它能够有效减少 IO 操作次数,从而提升性能。Parquet 推荐的行组大小为 512MB 至 1GB。此外,行组最好与 HDFS 的 Block 大小对齐,以减少跨 Block 的 IO 操作。理想的配置是行组大小和 HDFS Block 大小均为 1GB,并保证每个 HDFS 文件对应一个 HDFS Block。
数据页大小(Data page size):数据页是不可分割的存储单元。较小的数据页允许更精细的随机访问(如单行查找),但会增加 page header 的数量,从而带来空间开销。较大的数据页可以降低页面头部的开销,提升数据解析的效率。Parquet 推荐的数据页大小为 8KB,以在性能与空间利用率之间取得平衡。
总结来看,Parquet 文件格式通过行组、列块、页面三级结构,结合丰富的元数据信息和多种编码方式,达到了高效的数据存储和读取性能。其列式存储特性使得数据的压缩率大幅提高,并能高效支持大规模的并行查询。对于需要处理海量数据的场景,Parquet 是一种高效而可靠的数据存储格式。
4. Python使用Parquet
4.1 安装依赖并导入
1 | pip install pyarrow pandas |
1 | import pyarrow as pa |
4.2 定义schema
1 | schema = pa.schema([ |
4.3 导入数据
1 | data = [ |
4.4 生成parquet文件
1 | compression_method = 'gzip' #(snappy、lzo、brotli ...) |
4.4读取parquet文件并且查看格式信息
4.4.1 读取parquet文件
1 | read_table = pq.read_table("exmaple.parquet") |
1 | id speeds trajectory |
4.4.2 查看schame&元信息
1 | parquet_file = pq.ParquetFile("example") |
1 | 元信息: |
4.4.3 查看列信息
1 | row_group = parquet_file.metadata.row_group(0) |
1 | 列 0 (id) 信息: |
4.4.4 查看列编码方式
1 | for col_idx in range(parquet_file.metadata.num_columns): |
1 | 列 0 (id) 编码方式: |
5. 总结
本文详细介绍了 Apache Parquet 格式的原理与实践,重点讲解了其列式存储结构、嵌套数据支持、编码与压缩技术、以及如何在 Python 中使用 Parquet 文件。Parquet 的设计充分利用了列式存储的优势,特别是在大数据分析场景中,它能够显著提高查询效率并有效节省存储空间。
列式存储优势:Parquet 的列式存储方式使得在进行数据分析时,可以只读取所需的列,减少了不必要的磁盘 I/O 操作。此外,列式存储能高效地压缩数据,特别是对于重复性高的数据,能够显著减少存储空间的占用。
复杂嵌套结构支持:通过使用 Repetition Levels 和 Definition Levels,Parquet 能够高效处理复杂的嵌套数据结构,例如 List 和 Map。这种设计让 Parquet 格式在处理包含多个嵌套字段的复杂数据时,保持高效且灵活。
编码与压缩技术:Parquet 支持多种编码方式(如 PLAIN、DICTIONARY、RLE 编码等)和压缩算法(如 Snappy、GZIP、LZO 等)。这些技术帮助优化存储空间并提升数据读取性能。在不同的场景下,用户可以选择适合的编码和压缩方法,以平衡存储与速度的需求。
Python 使用 Parquet:通过
pyarrow库,Python 用户能够轻松地创建、读取和操作 Parquet 文件。示例代码展示了如何定义 Parquet 文件的 schema、将数据导入并生成 Parquet 文件,以及如何读取 Parquet 文件并查看其元数据和编码信息。性能优化:Parquet 的设计考虑了并行处理,支持高效的列读取操作,这对于大规模数据处理非常重要。它通过将数据划分为行组(Row Groups)、列块(Column Chunks)和页面(Pages),使得分布式计算框架如 Hadoop 和 Spark 能够高效地处理数据。
总的来说,Parquet 是一种功能强大的数据存储格式,它结合了列式存储的优势与高效的压缩、编码技术,特别适合用于大数据分析和大规模分布式计算环境中。